Multimodal LLMs are blind
2025-08-23
Tagged: llms, software engineering, cartesian tutor
Recently, I’ve been trying to get multimodal LLMs to help me parse chemistry exams from PDFs. It’s been mostly positive - overall, the LLM helps bring it down to 15 minutes per exam to transcribe and parse the PDF, screenshot/crop diagrams and chemical structures by hand, and then do Q/C. This task is far faster than pre-LLMs, but I was surprised that multimodal LLMs weren’t able to do the image cropping steps. This pushed me to figure out how exactly multimodal LLMs worked, and why they were failing the way they were.
In this essay, I review the current architecture and limitations of the latest generation of VLMs.
How do multimodal LLMs work in theory?
For the full details, I highly recommend Sebastian Raschka’s extensive literature review.
I’ll give a TL;DR here.
- Images are broken up into tiles (roughly 512x512 to 768x768, depending on the model).
- Each tile is processed by a neural network (convnet or ViT), generating an image embedding.
- The image embedding is transformed into the same space as either the input token space, or one of the intermediate layer’s transformer value space (e.g. a query/key/value is computed for the image).
Based on the billing strategy, it seems that each tile is charged on the order of 256 tokens, implying that the image’s encoding consumes the same number of representation bits as 256 normal text tokens. This seems reasonable, since with typical font/spacing, a tile of text might contain 100-200 tokens of text.
How do multimodal LLMs work in practice?
Here are some of the oddities I observed while working on my project.
- They are great at extracting conceptual information. When Claude (Sonnet 4) was given an image of four molecular structures, it correctly identified them as nitrobenzene, nitrosobenzene, benzenesulfonic acid, and phenyl nitrate.
- Claude (Sonnet 4) hallucinates page numbers when asked which page an image is on. So it isn’t told the ordering of the images passed in as attachments, and even when page numbers are present in the footer section of the PDF, the LLM can’t correctly use those page numbers.
- Claude (Sonnet 4) also hallucinates location within the page, claiming an image is on the left or right side of a page when it is not.
- When Gemini (2.5 Pro) was asked to generate a bounding box for the molecular structure of sucrose, it instead generated a bounding box for the literal word “Sucrose” that was present as a caption within the image.
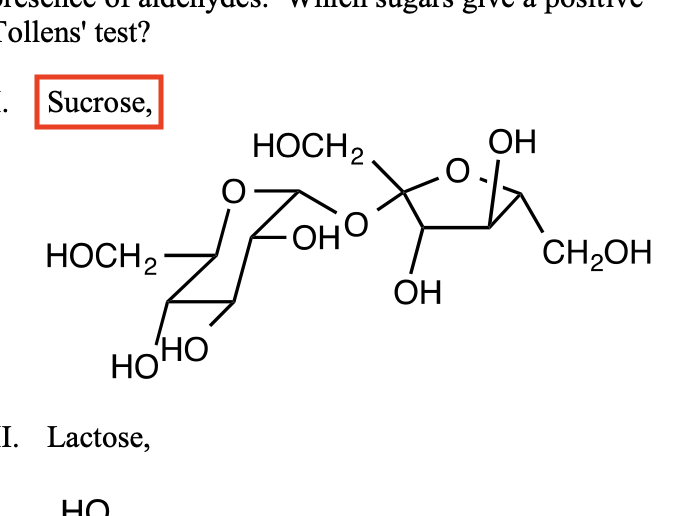
- When Gemini was asked to generate bounding boxes for the four molecular structures identified by Claude, it gave me back bounding boxes for the benzene ring, excluding the text “SO3H”.
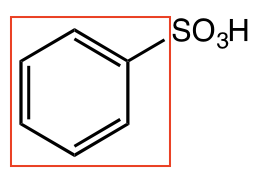
Multimodal LLMs use screenreaders
Multimodal LLMs do not see in any traditional human sense of the word. I would describe their current architecture as akin to using a screenreader that generates a ~250-word caption of the image. This is an imprecise analogy - image embedding directly maps to the latent space and no text caption is ever generated. But it gets one key detail correct: if the data isn’t in the caption, it’s invisible to the LLM.
The LLM gets no second chance to reinspect the image after seeing the system/user prompts. It relies on a one-size-fits-all captioning system that operates for all the use cases that people could possibly want to do: bounding box extraction, text transcription, image descriptions, etc. etc.. Similar issues probably exist for other input modalities - audio, video, etc..
I would love for Gemini’s bounding boxes to be more reliable and precise. Right now it’s only 80% reliable, and it is not a reasonable use of my time to try and build error correction layers on top of a primitive that’s only 80% reliable.
Unrelatedly… I strongly suspect Gemini “cheats” at text transcription tasks by passing in a supplemental OCR text extraction of the image. I have thrown dense tables full of numbers (think 10-columns, 50 rows of 6-digit numbers) at it, and verified that it can basically accurately transcribe them. This seems like it should not be possible under the architecture described above. It also maybe explains the inability to handle chemical structures containing text-like snippets.
Conceptually, I don’t really see an issue with letting the transformer’s attention mechanism “pay attention” to different parts of the image, according to the context of the user prompt. This is exactly how LLMs got so good at handling natural language, after all. Perhaps this is more of a computational/annotated dataset limitation?
Conclusion
Overall multimodal LLMs currently feel like GPT 4. They are clearly useful, and yet they are unreliable and not quite good enough. Do you remember when knowing how to get the LLM to follow your instructions was an art, when “prompt engineer” was hailed as the next big job title, and grandmas everywhere were being held hostage? Nowadays we just tell the LLMs what to do and they do it pretty reliably.
The image input facilities of multimodal LLMs feel like they are at the “threaten grandma” stage. The situation will almost certainly improve in a year or two. I can see many architectural improvements that can get LLMs to have the same “reasoning token” flavored breakthroughs on image processing; there is really no reason multimodal LLMs shouldn’t get to take a second look at the image with a more specific context in mind.